Last Updated: 04 August, 2023
Replication is the process of making copies of data on various servers and keeping track of them. With multiple copies of the same data on different database systems, replication gives us redundancy and makes data more accessible.
A database can be safeguarded against the loss of a single server by utilizing replication. We are also able to recover from malfunctions in our hardware and disruptions in our service thanks to replication. If we have additional copies of the data, we will be able to designate one of them to either backup, reporting, or disaster recovery.
There are couple of reasons for using Replication:
In Replication, if one server goes down we can access data from the another server.
High availability of data.
Recovery from disaster.
There is no downtime required for maintenance (such as backups, index rebuilds, or compaction).
Read scaling (extra copies to read from).
Replica set is transparent to the application.
A replica set is a group of mongod instances that maintain the same data set. A replica set contains several data-bearing nodes and optionally one arbiter node.
In the replica set, there will be only one primary node, and the remaining nodes will be secondary nodes.
Only the primary node receives all write operations in the replica set. The primary node records all changes to its data sets in its oplog (operation log).
The secondaries node replicates the primary's oplog and applies the operations to their data sets such that the secondaries' data sets reflect the primary's data set asynchronously.
A replica set can have up to 50 members but only 7 voting members in MongoDB.
We can see the diagram of the replica set below:
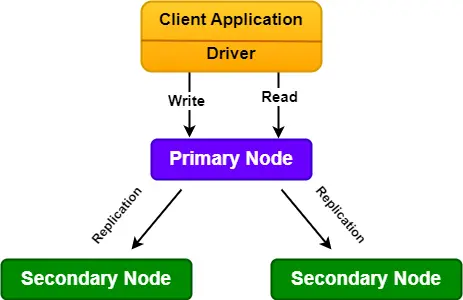
All secondary nodes in the replica set are connected to the primary node. There is one heartbeat signal from the primary node. When the primary node goes down, the secondary node cannot get the heartbeat signal.
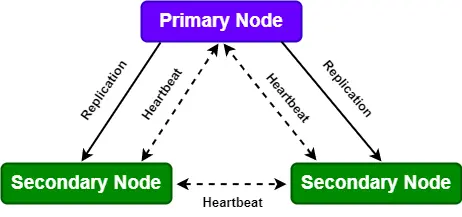
The secondary node waits 10 seconds for the heartbeat signal before determining that the primary node is not down. Then, it chooses the new node as the primary node. Write queries do not execute until a secondary node is designated as the primary node, whereas read queries function ordinarily. According to the replica configuration settings, the nomination of a secondary node as the primary node cannot exceed 12 seconds.
See the below diagram:
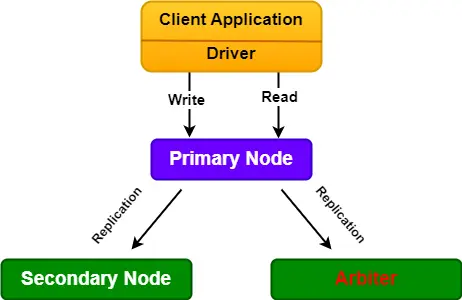
What is an Arbiter Node?
Arbiters are instances of MongoDB that are part of a replica set but do not store data. Arbiters participate in elections in order to break ties. If the number of members in a replica set is even, we can add an arbiter to it. The Arbiters node has minimal system resources and does not need dedicated hardware.
Important notes about Arbiters node:
Do not run an arbiter on a system that also hosts the primary or secondary members of the replica set.
In general, it is best to avoid deploying more then one arbiter for each replica set.
What is an Oplog?
The operations log, or oplog, is a special capped collection that keeps track of all actions that change the data in our databases.
That's all, guys. I hope this MongoDB article is helpful for you.
Happy Learning... 😀
Please share this article on social media to help others.
feedback@javabytechie.com